PageRank (AKA the Google Algorithm)

이번 장에서는 위의 세 가지 항목에 대해서 학습합니다. Page Rank, Personalized Page Rank, Random Walk with Restarts가 그것입니다.

Page Rank는 마치 자신의 importance를 내가 연결한 다른 page에 배분하는 것과 같습니다. 내 page가 3개의 page에 연결되어 있다면 3개의 page에 동등하게 내 importance를 배분합니다.

그리고 importance 배분은 위의 $\mathbf{r}=\mathbf{M}\cdot \mathbf{r}$으로 간단하게 나타낼 수 있습니다. Toy network해보면 금방 이해가 됩니다. 주의할 점은, 보통 행이 i 열이 j인데 여기서는 표기가 반대로 되어있다는 것입니다.. 그런데 의미상으로 이 표기가 맞습니다. 보통 행에 해당하는 source에서 열에 해당하는 destination으로 흐르는데, 이 예시에서는 반대입니다. source가 열이고 destination이 행입니다.

이 슬라이드의 예시를 보면 바로 이해가 가실겁니다.

Random하게 움직이는 web surfer를 상상해봅시다. $p(t)$는 i번째 원소가 time t에 surfer가 page i에 있을 확률입니다. Stationary한 상태를 찾는다면 각 page의 중요도를 파악할 수 있습니다. 마치 eigenvalue가 1인 eigenvector를 찾는 것 과 같습니다.

Eigenvector가 곧 importance가 됩니다. 그런데 이걸 구하는 것은 computatoinaly cost inefficient한 작업입니다. Iterative한 manner로 접근하여 문제를 해결할 수 있는데, $\sum_{i}^{} |r_i^{t+1}-r_i^{t}|<\epsilon$일 때 까지 반복합니다. 보통 시작은 균등한 벡터(1/N)가 됩니다.

이번 장의 요약입니다.
PageRank: How to solve?

Page rank의 문제점이 있는데, 1. 과연 수렴할까? 2. 우리가 원하는 결과로 수렴할까? 라는 문제로 나누어볼 수 있습니다.

과연 수렴할까에 대한 문제로 spider trap의 존재를 언급할 수 있습니다. 특정 node group에 들어온 다음 web surfer가 나가지 못할 수 있는 것 입니다. $\beta$ 확률로는 원래 룰을 따르고, $1-\beta$ 확률로 랜덤 페이지로 점프하도록 하면 문제를 해결할 수 있습니다. 스파이더 트랩 밖으로 텔레포트 하는 셈입니다.

우리가 원하는 결과로 수렴할까에 대한 문제도 고려해야 합니다. 어떤 페이지는 dead ends 존재하는데, dead ends를 만나면 모든 node에 동일하게 1/N의 확률로 방문하도록 할 수 있습니다.

구글은 모든 경우에 대해서 $\beta$ 확률로 모든 node에 대해 rbsemdgkrp teleport하게 만들었습니다. Spider trap과 Dead ends의 문제를 모두 해결할 수 있는 간단한 방법입니다.

예시를 보자면 위처럼 각 페이지의 중요도가 바뀌는 것을 볼 수 있습니다.

이번 장의 요약입니다.
Random Walk with Restarts and Personalized PageRank

위 그래프에서 어떤 node가 서로 가깝다고 정의할 수 있을까요?

서로 최단 경로에 있는 node도 있고, common neighbor가 있는 node도 있습니다. 다양한 node 관계가 있는데, 어떤 node가 가장 related 될까요?

Personalized PageRank는 teleport할 node들에 대한 proximity를 계산합니다. Random Walks with Restarts는 starting node로 다시 돌아갑니다.

Random Walks with Restart는 위의 알고리즘으로 표현 가능힙니다. Random Walks with Restart는 직관적이지만 좋은 solution입니다. Random Walks 과정에서 Multiple connections, Multiple paths, Direct and indirect connections, Degree of the node가 표현되기 때문입니다.

이번 장의 요약입니다. 각 알고리즘이 restart 확률 S를 어떻게 정의하는지에 대한 차이를 확인하면 되겠습니다.
Matrix Factorization and Node Embeddings

Node similrity를 A matrix로 두고, 두 node embedding의 내적이 그 A matrix의 원소가 되게 한다면, 생각보다 쉽게 node embedding을 구할 수 있습니다. Matrix factorization 자체가 node embedding의 결과가 되는 셈입니다. [N by K]의 K dimension으로 embedding한다면, K를 적절히 조정하여 embedding 차원을 정할 수 있습니다.

DeepWalk의 경우는 위 식의 결과로 나온 matrix를 factorization 시킨다고 합니다. 자세한 내용은 위의 논문을 확인해야 할 것 같습니다.
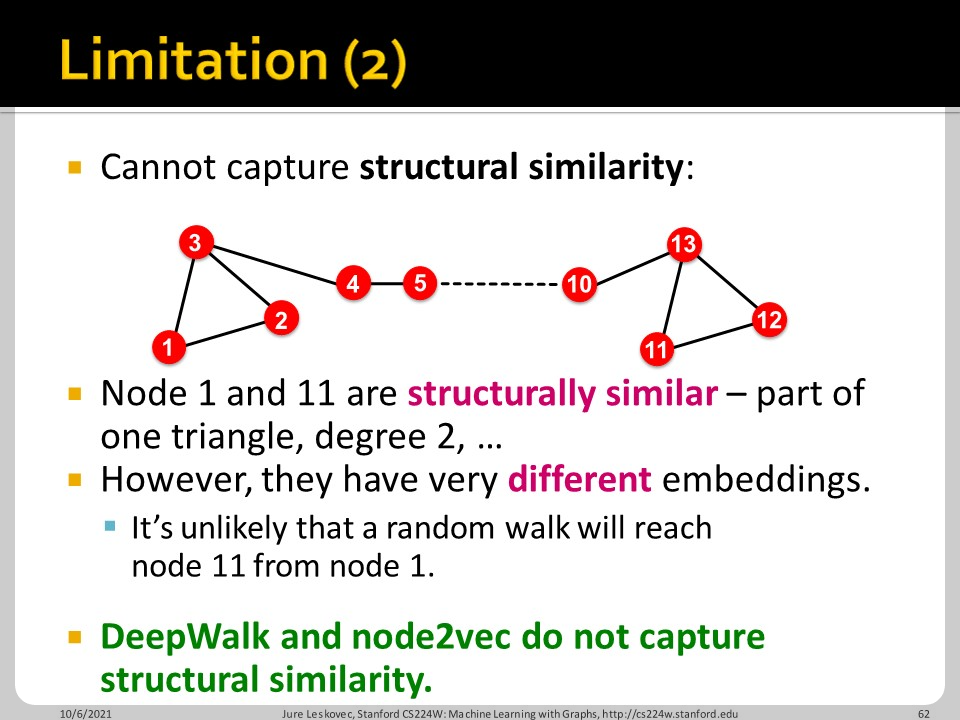
하지만 Random Walk based 방법도 단점이 있습니다. Training set에 없는 node를 훈련시킬 수 없고, 구조적 유사성을 학습하지 못합니다. (슬라이드 내용) 또한 feature vector를 활용하지 못한다는 단점도 존재합니다.

이번 장의 요약입니다.
'Machine Learning > CS224W' 카테고리의 다른 글
| CS224w - 06. Graph Neural Networks Part 1 (0) | 2022.03.16 |
|---|---|
| CS224w - 05. Message Passing and Node Classification (0) | 2022.03.08 |
| CS224w - 03. Node Embeddings (0) | 2022.02.18 |
| CS224w - 02. Traditional Methods for Machine Learning in Graphs (0) | 2022.02.17 |
| CS224w - 01. Intro (0) | 2022.02.15 |



