Scaling Up Graph Neural Networks and Modern Applications

일반적인 learning scheme에서 large data에 대해서는 mini-batch에서 SGD를 수행합니다.

하지만 GNN에서는 mini-batch 내에서 노드를 샘플링하면 노드가 서로 멀리 떨어진 상태일 확률이 높습니다. 따라서 mini-batch에서 얻어진 node들을 가지고 neighborhood update를 하기 어렵습니다.

이런 문제를 피하기 위해서 full batch로 학습할 수도 있지만, GPU memory의 문제로 불가능합니다.
따라서 본 강의에서는 subgraph를 이용한 학습(Neighbor Sampling, Cluster-GCN), 그리고 feature preprocessing으로 GCN을 단순화한 학습(Simplified GCN)에 대해 학습합니다.
GraphSAGE Neighbor Sampling: Scaling Up GNNs

GNN 문제 설정 상황에서, 노드 하나를 학습시키는데 필요한 건 K-hop의 neighborhood입니다. Mini-batch에 M개의 node가 있다면, 우리는 M개의 computational graph를 얻으면 됩니다.

따라서 M개의 노드에 대해서 M개의 computational graph를 얻는 방법으로 averaged loss를 구할 수 있습니다. 매우 직관적인 방법입니다. 하지만 여기에도 문제가 있습니다.

첫 번째 issue는 노드마다 K-hop neighborhood를 모두 구해서 computation graph에 넣을 경우, 한 노드마다 계산할 정보가 너무 많다는 것입니다.

두 번째 issue는 layer 수(K)가 커지면 computation graph가 기하급수적으로 커진다는 것입니다. 그리고 중간에 hub node가 포함되면 더 빠르게 증가합니다. 따라서 보다 compact한 computation graph를 만들 필요가 있습니다.

이를 위해 neighborhood sampling에서는 각 hop마다 H개의 이웃 노드를 샘플링합니다. Computational graph를 pruning 한다고도 볼 수 있습니다.

H가 작으면 작을수록 효율적이지만 neighbor aggregation의 variance가 커져 unstable training이 발생합니다. 그리고 샘플링하더라도 layer num K에 따라서 computation graph는 여전히 지수함수적으로 증가합니다.

Sampling을 어떻게 할지의 문제도 있습니다. Random sampling은 빠르지만 optimal은 아닐 수 있습니다. 반대로 random walk with restarts는 중요한 노드를 샘플링하기 위한 전략인데, random walk을 통해 neighbor scoring하는 것입니다.
Cluster-GCN

Neighbor sampling에서의 이슈를 다시 살펴보면, mini-batch 내에서 서로 이웃을 많이 공유하면 서로 computation graph를 공유하게 됩니다. 이는 연산의 redundancy를 증가시킵니다.

Full-batch로 학습할 때는 같은 embedding을 여러 번 반복할 필요가 없습니다. 따라서 subgraph를 sampling하고 subgraph를 full-batch로 학습하는 방법으로 학습을 진행시킬 수 있습니다.

그렇다면 어떤 subgraph가 GNN 학습에 좋은 그래프일까요? GNN은 node embedding을 edge를 통한 message passing으로 update합니다. 따라서 edge connectivity를 original graph만큼 잘 살린 sub graph가 적합할 것입니다.

기존의 구조를 잘 살린 subgraph가 좋은 graph일 것입니다. 왼쪽의 subgraph에 해당합니다.

실제 그래프는 커뮤니티 구조를 가져서 작은 여러 개의 커뮤니티들로 쪼갤 수 있습니다.
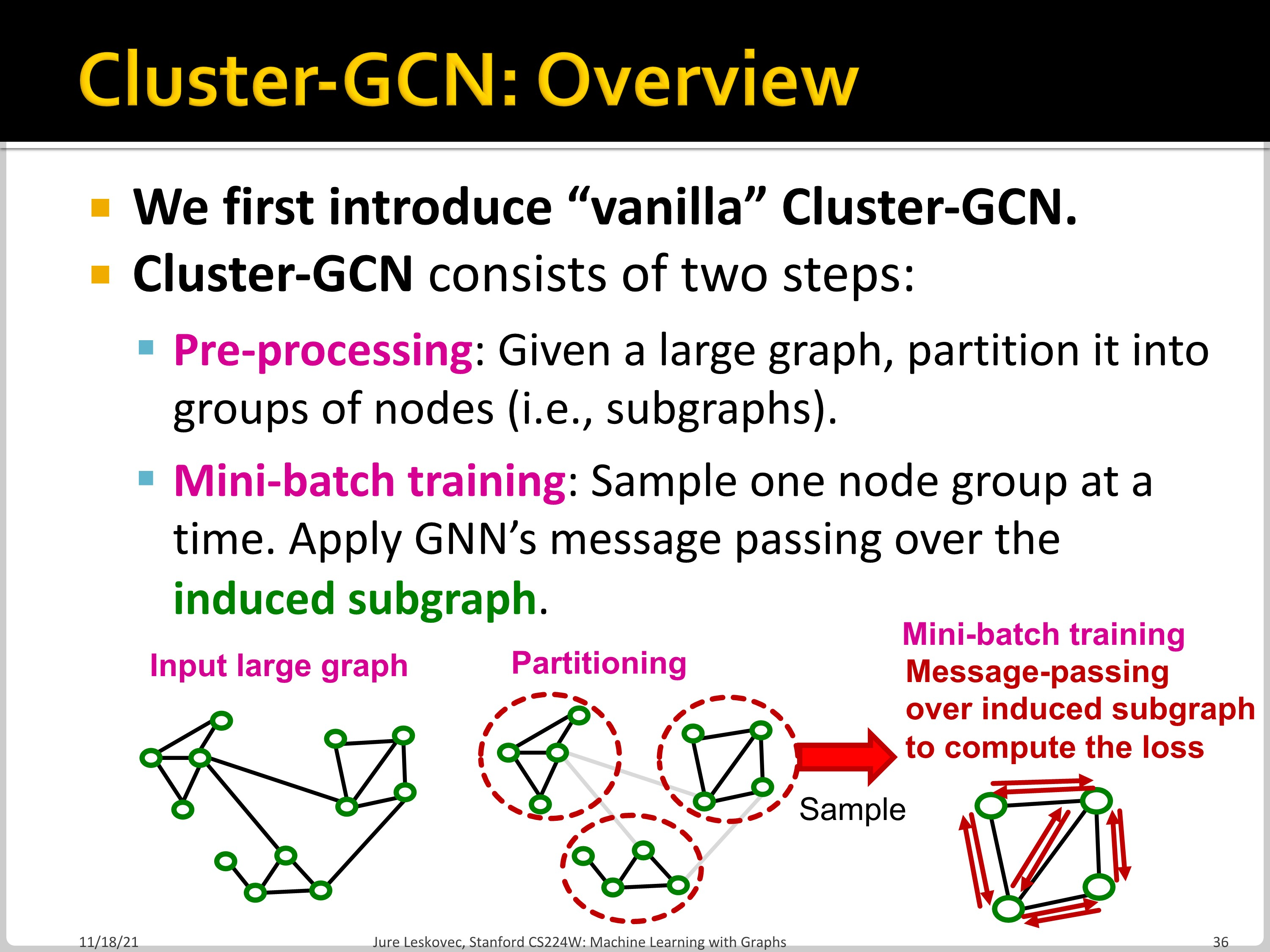
Vanilla Cluster-GCN은 두 단계로 나뉩니다. Pre-processing에서는 하나의 large graph를 여러 개의 subgraph로 나눕니다. 그다음 Mini-batch training에서 하나의 subgraph에 대해서 message passing 수행합니다.

Pre-processing 단계에서 C 개의 group으로 나누어지게 되고, 이때 그룹 사이의 edge는 포함하지 않습니다.

Subgraph $G_c$ 에 대해서 layer-wise node update가 진행되는 모습입니다. 이 방법은 각각 어떤 issue를 갖고 있는지 확인해보겠습니다.

첫 번째로 group 사이의 link가 사라져 그룹 간의 정보가 전달되지 못합니다. 이로 인하여 성능이 저해됩니다.

두 번째로 graph community detection algorithm은 비슷한 노드들을 하나의 그룹에 포함시킵니다. 이러한 node group은 전체 데이터의 일부만 설명할 수 있습니다.

세 번째로 하나의 node group은 그래프 전체를 표현하기에 충분히 다양하지 않습니다. SGD를 진행하는 과정에서 노드 그룹이 달라질 때마다 변동성이 커지고, 수렴이 느리게 나타납니다. 이에 따라서 Advanced Cluster-GCN이 등장하였습니다.
'Machine Learning > CS224W' 카테고리의 다른 글
| CS224w - 17. Advanced Topics in Graph Neural Networks Part 2 (0) | 2022.12.05 |
|---|---|
| CS224w - 16. Advanced Topics in Graph Neural Networks Part 2 (0) | 2022.12.04 |
| CS224w - 16. Advanced Topics in Graph Neural Networks Part 1 (0) | 2022.12.04 |
| CS224w - 15. Deep Generative Models for Graphs Part 2 (0) | 2022.11.30 |
| CS224w - 15. Deep Generative Models for Graphs Part 1 (0) | 2022.11.23 |



