This article summarizes RL Course by David Silver - Lecture 1: Introduction to Reinforcement Learning.

Reinforcement learning has no supervisor. The reward signal guides the agent if things are going right or wrong. The feedback is delayed. Some feedback takes hours to obtain, such as go game. The data that the agent receives is sequential. So the action of the agent affects the information it receives.
The reward hypothesis assumes a properly planned reward will lead the agent to the goal. By maximizing the expectation of accumulated reward, the agent can achieve its goal.
To achieve a long-term goal, the agent may sacrifice immediate reward. We have to study to succeed in the exam, not play the game, even if playing the game gives us immediate pleasure. The agent learns this lesson by trial and error.
Every time step, the agent observes the environment by itself. And every time step, the environment receives action from the agent and emits the observation.

History is the whole sequence of agents' experiences and behavior. And that history produces a state in an unknown type of function.

The agent cannot observe the whole information of the environment. Some aspects of the environment's information may be just noise. Therefore, the state is the agent's internal representation. In other words, Set≢
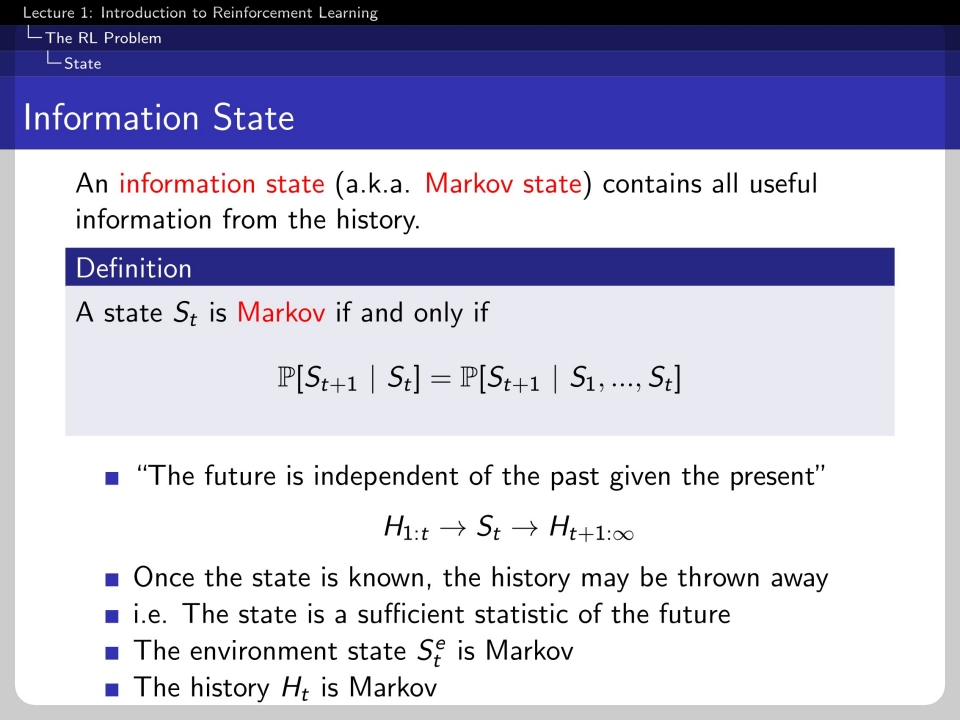
If the state has a Markov property, the present contains all information about the past.

If the word is fully observable, the agent's state and the environment's state are the same. This is a Markov decision process(MDP) with a Markov property and fully observable characteristics.

There is a different problem set for the partially observable environment, which we call the partially observable Markov decision process. If the environment is partially observable, the agent should estimate the environment by its belief or model.

In RL, the agent should have a policy(behavior), value function, and model. The value function estimates the value of the current state. Model is the way the agent understands the environment.

Policy maps the state to action. Some policies are deterministic, while others are not. We use the character \pi to represent a policy.

The value function is the prediction of future rewards. We depreciate the future reward by \gamma, because it is mathematically efficient, and an immediate reward is usually better.
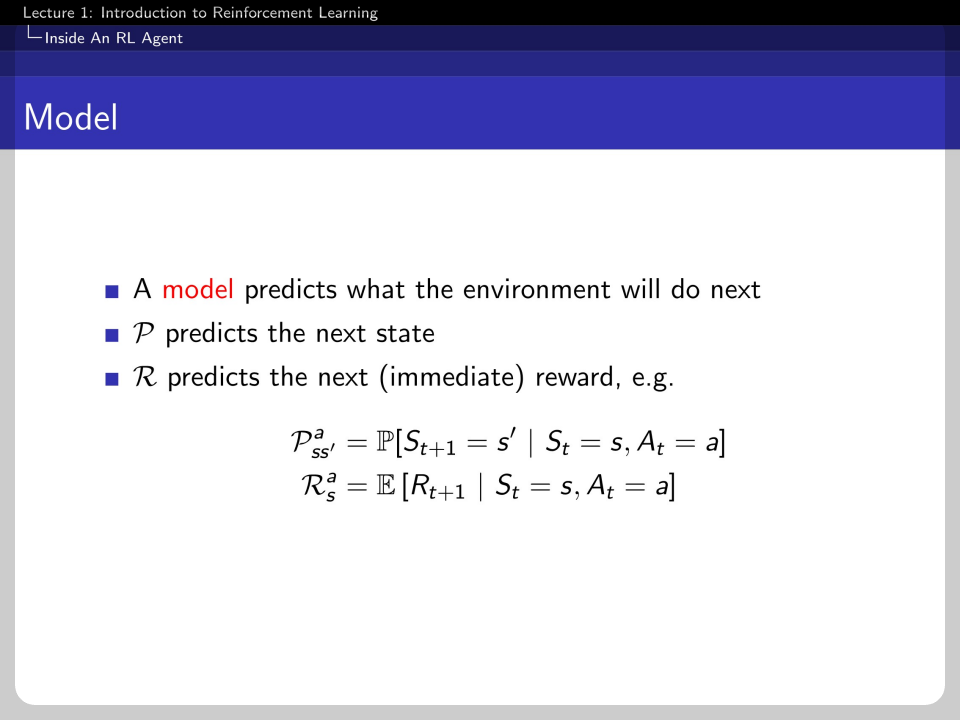
P is the transition probability, and R is an estimated reward. This model is the basis of policy and value function because it helps the agent predict the future.

This is the form of policy function, where there is an action for every state.
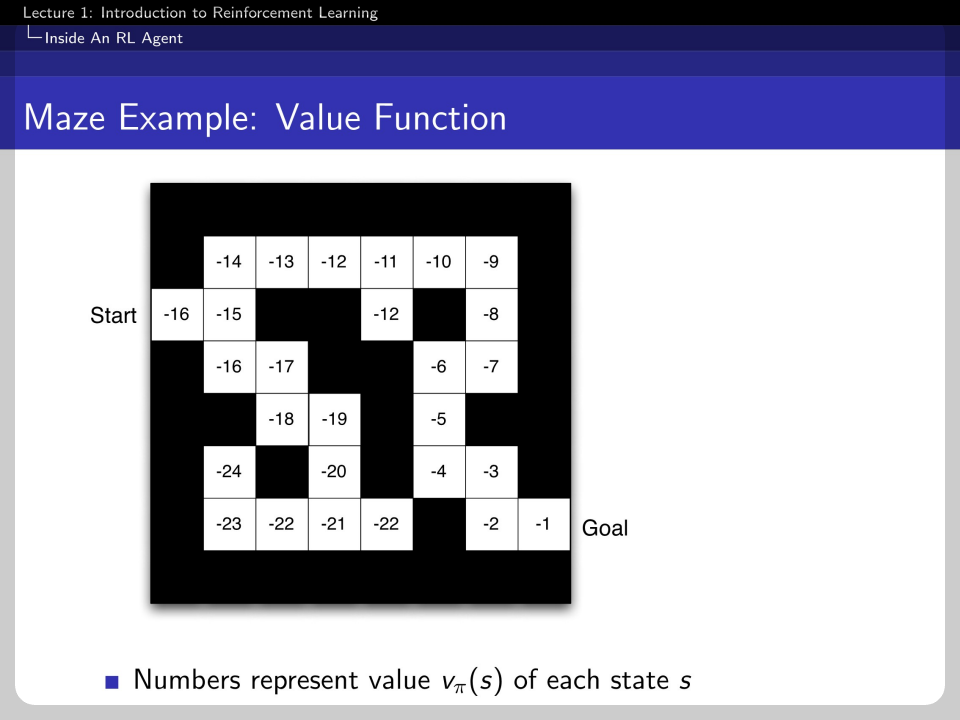
This is an example of a value function where every state has its estimation of the value.

The agent's model may be imperfect. So the model's transition updates as the agent explore the environment.

We can categorize the RL agent as Value-based, policy-based, and actor-critic. Actor critic uses both value function and policy.

This is another hierarchy of RL agents, which is model-free and model-based.
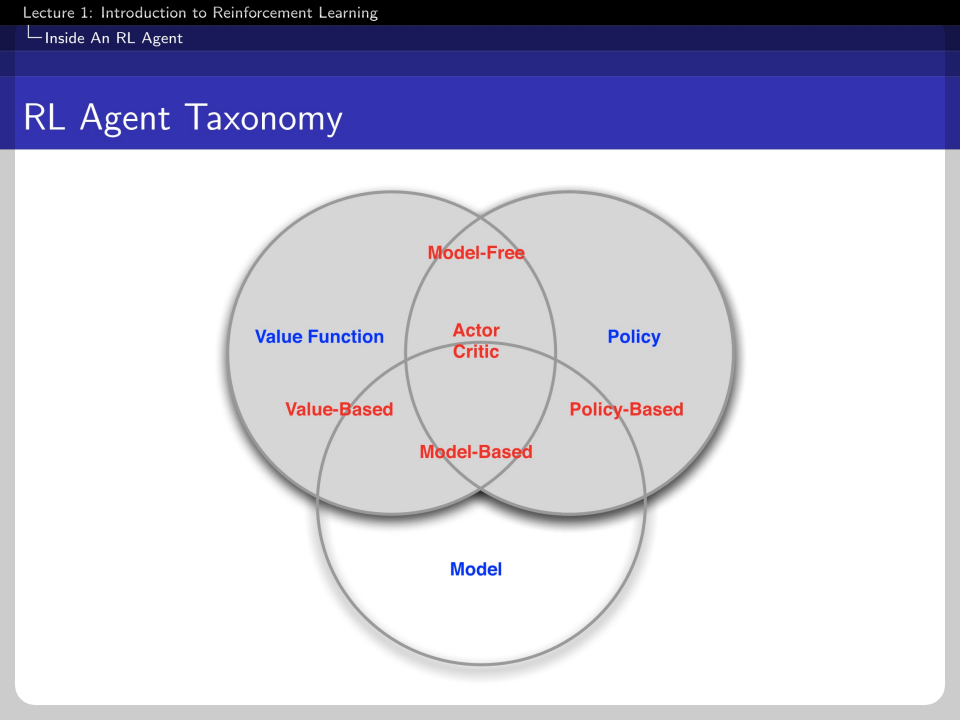
The taxonomy can be visualized as above.

There is a big difference between reinforcement learning and planning. RL does not know the environment, and the agent should explore by updating its information about the environment. However, planning has full details on the environment. This means the agent can simulate the exact future.
Reinforcement learning is like trial-and-error learning. The agent should discover a good policy. From its experiences of the environment. While planning is a full simulation, just like Dr. Strange.
There is two different behavior of the Agent. Exploration and Exploitation. Exploration finds more information about the environment. Exploitation exploits known information to maximize reward.

In the prediction stage, we evaluate the future with our known policy. In the control stage, we find the best policy by known model.
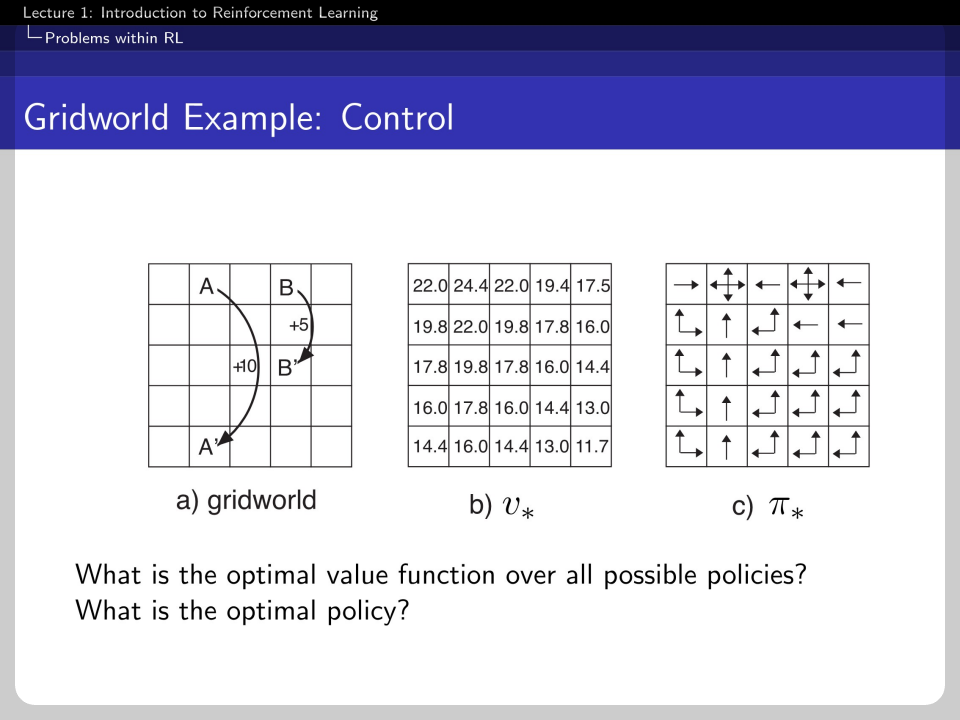
The value function v_{*} deduces a value with all possible policies. The policy guides behavior in every possible state.
'Machine Learning > Reinforcement Learning' 카테고리의 다른 글
| RL Course by David Silver - Lecture 4: Model Free Prediction (0) | 2022.08.04 |
|---|---|
| On-Policy, Off-Policy, Online, Offline 강화학습 (0) | 2022.06.23 |
| RL Course by David Silver - Lecture 3: Planning by Dynamic Programming (0) | 2022.05.18 |
| RL Course by David Silver - Lecture 2: Markov Decision Processes (0) | 2022.05.03 |



